
前回の続きになります。前回の記事はこちら。今回は帳票仕分けについて説明します。

なぜ帳票仕分けが必要なのか
お客様から受領する紙文書は、一つの形式だけということは少なく、数種類の形式があります。 複数のお客様から複数パターンの形式の紙文書が一斉に送られてくるのが普通ですので、これをそれぞれの形式毎に仕分ける作業が必要となります。AI-OCRは、帳票の種類ごとにAIモデルを定義するため、間違った形式の帳票を読み取ると、認識率が落ちるからです。
帳票仕分けの方法
「紙文書の形式を自ら作ることができるケース」と、「何らかの事情で帳票形式の作成に制約があるケース」で対応が異なります。
A.紙文書の形式を自ら作ることができるケース
「特徴のある文字列を決まった場所に仕込む」「決まった場所にQRコード/バーコードを仕込む」ことで、お客様から受領した帳票を識別します。識別は自前のプログラムを作ることもできます(※)が、帳票仕分けの専用製品・サービスを購入した方が精度は高いと思います。
※Pythonだと、openCV、pillow、pyzbarなどを使って、対象箇所を切り取り、バーコードを読み込む機能を用意
B.何らかの事情で帳票形式の作成に制約があるケース
帳票全体の枠線の形状から、帳票種類を識別します。ただし、Aパターンより認識率が落ちます。例えば、似た枠線形状の帳票が複数あると、識別が難しいです。
自前でプログラムを作る方法はAパターンよりも難しいです。(後述しますが、私はうまくいきませんでした。)帳票仕分けの専用製品・サービスを購入するのがよいと思います。
失敗事例(PythonでBパターンを分類してみる)
帳票全体の枠線の形状から、帳票種類を識別できないかPythonプログラムで試してみました。結果は失敗。アプローチが不味かったのかもしれませんが、高精度のプログラムを自前で作るのは難しそうです。
世の中の定型帳票読み取りの帳票仕分けサービスは、今回ご紹介したようなやり方ではなく、枠線の画像を白と黒の2色のみに二値化処理して、スキャナ読み取り時のズレを補正した上で、黒の位置を直接比較したりしているのかもしれません。(すいません。未調査です。。。)
失敗事例1:OpenCVの特徴量検出関数を使う
OpenCVのakazeなどのライブラリを利用して、帳票の枠線が特徴として抽出できないか試してみました。結果は失敗。枠線を特徴として認識してもらえませんでした。実際には、枠線の他に記入された文字も存在するので、更に読み取りの難易度は上がると思われ、このやり方はうまくいきそうもありません。
OpenCVの特徴量検出は、写真などもっとはっきりした特徴があるものを想定しているので、帳票みたいな画像はフラットにしかならないのかもしれません。
失敗事例2:ディープラーニングで画像分類
オープンソースニューラルネットワークライブラリであるKerasを使って、ディープラーニングで帳票種類を識別できないか試してみました。こちらも失敗。学習のための良質の画像データが少ないせいかもしれません。こちらはもう少し頑張ればできるのかも。
失敗作ですが、一般的な画像分類ではそのまま使えそうなので、サンプルプログラムを参考までに掲載します。掲載の順番でプログラム実行すれば試行できます。
pdfファイルを1枚ずつ分割
スキャナで読み取った段階で複数枚の帳票データが1ファイルになっている場合もあるので、1枚ずつに分離します。1枚ごとで帳票形式が異なるので。pdf形式でファイル保存した想定で、それをjpeg形式に変換する処理も合わせて行います。
# 実行時、パッケージが見つからなければ、pip install 〇〇〇でインストールして下さい。
import PyPDF2
import pathlib
import os
from io import FileIO
from pdf2image import convert_from_path
from pathlib import Path
# フォルダを指定してください。
indir = '(入力ファイルのフォルダを指定してください)'
outdir = '(出力ファイルのフォルダを指定してください)'
outdir_image = '(jpeg形式の出力ファイルのフォルダを指定してください)'
# フォルダ内のPDFを全て取得(*は任意の文字列)
pdffiles = list(pathlib.Path(indir).glob('*.pdf'))
# フォルダ内のPDFファイルを1つずつ処理
for pdffile in pdffiles:
# 拡張子pdfなしのファイル名取得
filename = pdffile.name
# pdfファイルを読み込み
pdffile_reader = PyPDF2.PdfFileReader(FileIO(pdffile,"rb"))
# 分割PDFファイルを作成、保存。また、分割PDFファイルをjpeg形式に変換したファイルも保存。
for page in range(pdffile_reader.numPages):
pdf_new = PyPDF2.PdfFileWriter()
pdf_new.addPage(pdffile_reader.getPage(page))
pageNo = format(page+1, '0>3')
filename_new = os.path.join(outdir, f'{filename}_{pageNo}.pdf')
with open(filename_new, 'wb') as f:
pdf_new.write(f)
output_file = Path(filename_new).stem
convert_from_path(filename_new, output_folder=outdir_image,fmt='jpeg',output_file=output_file)
画像水増し
学習データの帳票の数を水増しします。
画像データを毎回確認したかったため、11行目のFILE_DIRは都度変更していますが、面倒であればfor文でループさせる処理に変更ください。 ImageDataGenerator のパラメータの詳細については、kerasのサイトをご確認下さい。
import os
from keras.preprocessing.image import ImageDataGenerator
import glob
from tensorflow.keras.preprocessing.image import img_to_array, load_img
import numpy as np
# データの保存先(自分の環境に応じて適宜変更して下さい。)
FILE_DIR_PATH = ".\\workdir\\"
FILE_DIR = FILE_DIR_PATH + "image5" # ←ここを実行の都度変更して下さい。
FILE_PATH = FILE_DIR + "\\*.jpeg"
datagen = ImageDataGenerator(
rotation_range=10, # ランダムに回転
width_shift_range=0.05, # ランダムに水平シフト
height_shift_range=0.05, # ランダムに垂直シフト
brightness_range=[0.7, 1.0], # 明度を変更
fill_mode='nearest') # 入力画像の境界周りを埋める
for filepath in glob.glob(FILE_PATH):
img = img_to_array(load_img(filepath, target_size=None))
# datagenの入力4次元に合わせる(Height, Width, Channels)を(1, Height, Width, Channels)に変換
img = img[np.newaxis]
# 指定したディレクトリにランダム変換した生成画像を保存する。
i = 0
for batch in datagen.flow(img , batch_size=1,save_to_dir=FILE_DIR, save_prefix='gazou', save_format='jpeg'):
i += 1
if i == 5:
break ディープラーニングでモデルを作成
帳票分類のためのAIモデルを作成します。今回は、5種類の帳票形式がある想定のプログラムになります。
import os
import glob
import numpy as np
from tensorflow.keras.models import Sequential, model_from_json
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import array_to_img, img_to_array, load_img
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# データの保存先
FILE_DIR_PATH = ".\\workdir\\"
# フォルダがなければ作成
os.makedirs(FILE_DIR_PATH, exist_ok=True)
batch_size = 8 # バッチサイズ
num_classes = 5 # 分類クラス数
epochs = 300 # 学習の繰り返し回数
img_width = 32 # 入力画像の幅
img_height = 32 # 入力画像の高さ
img_ch = 3 # 入力画像はRGBの3ch
# データ初期化
data_x = [] # 画像データのベクトルを格納
data_y = [] # ラベル(画像データが何かを特定する情報)を格納
# ラベル0の画像データをロード
FILE_PATH = FILE_DIR_PATH + "image1" + "\\*.jpeg"
for filepath in glob.glob(FILE_PATH):
img = img_to_array(load_img(filepath, target_size=(img_width,img_height, img_ch)))
data_x.append(img)
data_y.append(0) # ラベル0を割り当て
# ラベル1の画像データをロード
FILE_PATH = FILE_DIR_PATH + "image2" + "\\*.jpeg"
for filepath in glob.glob(FILE_PATH):
img = img_to_array(load_img(filepath, target_size=(img_width,img_height, img_ch)))
data_x.append(img)
data_y.append(1) # ラベル1を割り当て
# ラベル2の画像データをロード
FILE_PATH = FILE_DIR_PATH + "image3" + "\\*.jpeg"
for filepath in glob.glob(FILE_PATH):
img = img_to_array(load_img(filepath, target_size=(img_width,img_height, img_ch)))
data_x.append(img)
data_y.append(2) # ラベル2を割り当て
# ラベル3の画像データをロード
FILE_PATH = FILE_DIR_PATH + "image4" + "\\*.jpeg"
for filepath in glob.glob(FILE_PATH):
img = img_to_array(load_img(filepath, target_size=(img_width,img_height, img_ch)))
data_x.append(img)
data_y.append(3) # ラベル3を割り当て
# ラベル4の画像データをロード
FILE_PATH = FILE_DIR_PATH + "image5" + "\\*.jpeg"
for filepath in glob.glob(FILE_PATH):
img = img_to_array(load_img(filepath, target_size=(img_width,img_height, img_ch)))
data_x.append(img)
data_y.append(4) # ラベル4を割り当て
# NumPy配列に変換
data_x = np.asarray(data_x)
data_y = np.asarray(data_y)
# 学習用データ(8割)/テストデータ(2割)に分割
x_train, x_test, y_train, y_test = train_test_split(data_x, data_y, test_size=0.2)
# 学習データを正規化(0~1に変換)
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# 正解ラベルをone hot形式に変換
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# モデルの作成
model = Sequential()
model.add(Conv2D(32,(3,3), padding='same', input_shape=x_train.shape[1:],activation='relu'))
model.add(Conv2D(32,(3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64,(3,3), padding='same', activation='relu'))
model.add(Conv2D(64,(3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
# トレーニング
# パラメータの詳細はこちらを参照下さい。 https://keras.io/ja/models/model/
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs,
verbose=1, # 進行状況の表示モード 0 = 表示なし,1 = プログレスバー,2 = 各試行毎に一行の出力
validation_split=0.1)
# モデルを評価
score = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', score[0]) # 「予測値」とのズレの大きさ
print('Test accuracy:', score[1]) # 正解率
# 作成したモデルを保存
open(FILE_DIR_PATH + "model.json","w").write(model.to_json())
model.save_weights(FILE_DIR_PATH + "weights.hdf5")予測!!
最後に、作ったAIモデルで予測します。サンプルプログラムは1枚だけを予測させていますが、実践的にはfor文でループさせてまとめて予測することになると思います。(この段階でうまく予測できず、挫折しましたが。。。)
import numpy as np
from tensorflow.keras.models import Sequential, model_from_json
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from tensorflow.keras.utils import to_categorical
# データの保存先
FILE_DIR_PATH = ".\\workdir\\"
img_width = 32 # 入力画像の幅
img_height = 32 # 入力画像の高さ
img_ch = 3 # 入力画像はRGBの3ch
# ラベル
labels =['IMAGE1','IMAGE2','IMAGE3','IMAGE4','IMAGE5']
# 作成したモデルを読み込む
model = model_from_json(open(FILE_DIR_PATH + "model.json", 'r').read())
model.load_weights(FILE_DIR_PATH + "weights.hdf5")
# 画像を読み込み、次元配列に変換(モデルの入力が4次元なので合わせる)
img = load_img(FILE_DIR_PATH + "test.jpg", target_size=(img_width, img_height))
img = img_to_array(img)
img = img.astype('float32') / 255.0
img = np.array([img])
# 予測
y_pred = model.predict(img)
# 予測結果の表示
number_pred = np.argmax(y_pred)
print("y_pred:", y_pred) # 出力値
print("number_pred:", number_pred) # 最も確率の高い要素
print("label_pred:", labels[int(number_pred)]) # 予測結果
事務を自動化した後の事務フロー
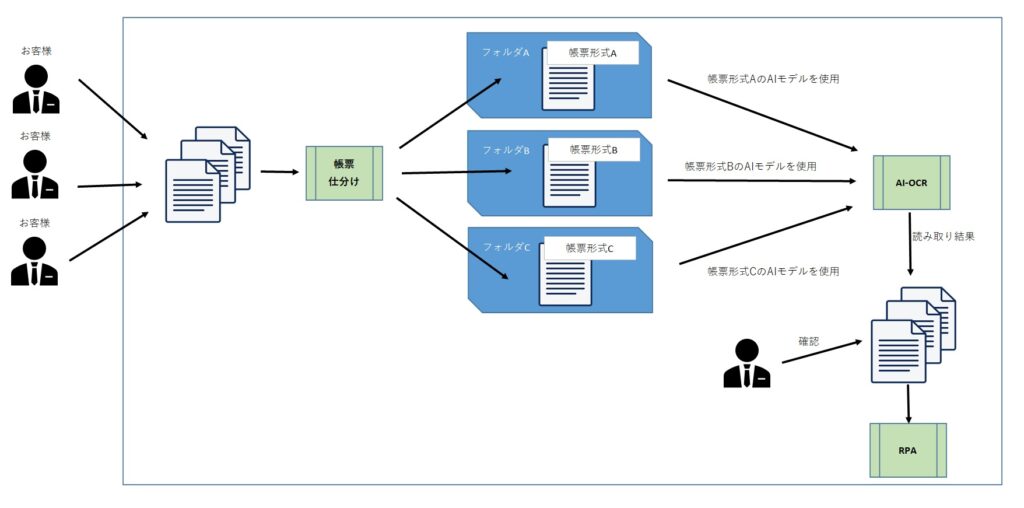
帳票仕分けを含めた事務自動化の流れは以下のようになります。
- 紙文書をまとめてスキャン。大量の画像データが所定のフォルダに置かれる
- 画像データに「帳票仕分けプログラム」を使い、同種類の画像データ毎に別フォルダに仕分ける
- 同種類の画像データを入れたフォルダ単位で、対応したAIモデルのAI-OCRに読み込ます
- AI-OCRの読み取り結果(電子データ)を、人が目で確認
- RPAを実行して、社内システムに自動入力
まとめ
帳票仕分けを含めた事務の流れについてまとめました。帳票仕分け機能は、スキャナやAI-OCRサービスに含まれているケースもあります。そういった製品・サービスを利用すれば、個別に帳票仕分けに関するサービスを購入する必要がなくなるので、販売会社に問い合わせてみて下さい。
次回はAzure Form Recognizer利用時のポイントについて説明します。
